

The Statistical Mirage of Clutch Hitting
This article was written by Harold Brooks
This article was published in 1989 Baseball Research Journal
Do clutch hitters exist? Not according to the most popular yardstick used to define them, says the author. Clutch hitting, he concludes, is “a mirage at best.”
IS THERE SUCH A thing as a clutch hitter? This question has been the subject of endless discussion through the years. Until recently, the evidence on the subject was purely anecdotal and often based on single or very limited numbers of events (Canton Fisk is a great clutch hitter because of one at bat in the 1975 World Series). As a result, most people would have answered the question “yes.” Recently, however, a little more data has been collected and more rigorous tests of the question have been attempted. In 1977, in the Baseball Research Journal, Dick Cramer concluded that clutch hitters definitely do not exist. Bill James and Pete Palmer supported this conclusion, although more cautiously, calling clutch hitting a “shadow” and an “optical illusion,” respectively.
In “The 1985 Elias Baseball Analyst,” the opposite conclusion is reached, They claimed that Cramer’s conclusion was wrong because the definition he used was improper. They defined the best clutch hitter as the man whose total batting average improved the most in late-inning pressure situations. (A late-inning pressure situation is one occurring in the seventh inning or later, with the batter’s team either tied or trailing by three runs or less, four runs if the bases are loaded.) Since the first publication of this idea, each successive “Analyst” has continued to stress the existence of clutch hitting. These comments reached their peak with the statement in the Milwaukee Brewer comment in the “1988 Analyst” that “a small group of shrill pseudo-statisticians has used insufficient data and faulty methods to try to disprove the existence of the clutch hitter.” However, using the published data in the “Analyst” for 1984 to 1987, the simple statistical analysis here shows that conclusion —that clutch hitters do exist – is blatantly untrue, at least according to the Elias definition. We cannot prove that clutch hitters do not exist, only that they do not exist as defined by Elias.
In 1985, Elias presented lists of the ten best and worst clutch hitters in each of 1983 and 1984 and then how those players had performed in the other year. They noted that the best in one year averaged out to being better than the norm in the other year, and the worst were worse than the norm in the other year. This procedure used only a small part of the available data, ignoring the vast majority of the players in between and how they performed. In 1988, they took players who had been above or below average each of two years and then saw how those players did in a third year. They found that the percentage of players in the “above both years” group who were above the next year was higher than the percentage of players who were mixed or below both years. This study neglected the degree to which players were above or below average. In other words, if a player was 1 point above his average in pressure situations each of the first two years and then was 1 point below in the third, this was a negative result for their hypothesis, while a player who was always above his average, but who went from 1 point above to 200 points above to I point above was a positive result, even though the former player was much more consistent in his clutch performance than the latter.
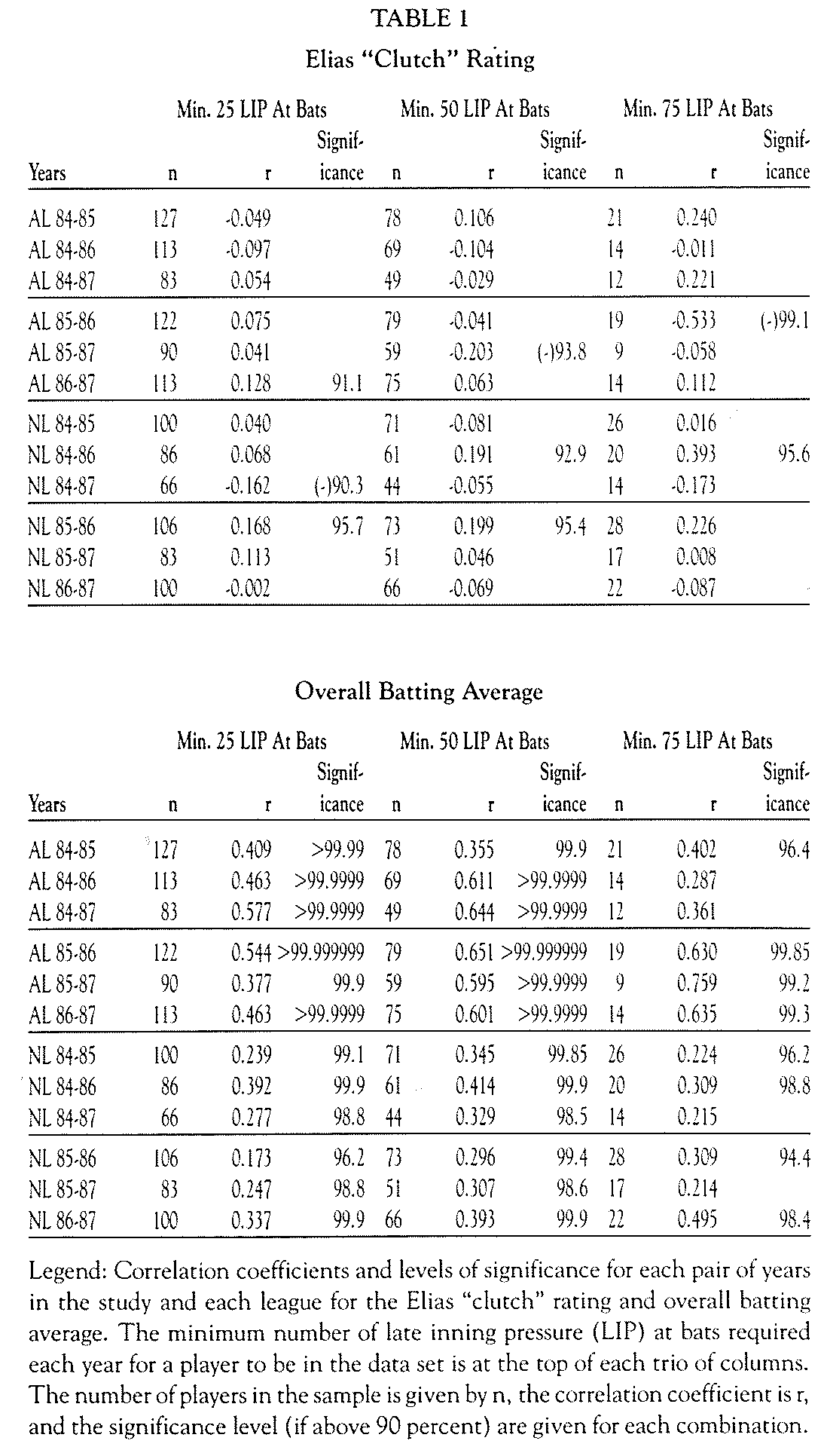
There are three basic methods we will use on the four years of data to look at this question. The first will be to compute correlations between the performances of players for each pair of years for each league. Secondly, we will consider the number of years a player performed better or worse in late-inning pressure situations than overall. Finally, we will look at the performance of those players who were substantially above or below their overall performance in late-inning pressure more than one time. For clutch hitting to be something more than a statistical artifact, we would expect (1) significant correlations in performance from year to year, (2) large numbers of players being either always “good” or “had” clutch hitters, and (3) that those players who were the best or worst more than once would consistently be on the same side (i.e. better or worse) of their overall performance. We will limit the data set to those players who have individual boxes in the “Elias Analyst” and who have a minimum of either 25, 50 or 75 late-inning pressure at bats in a given year. (Assuming that the effect is real, one would expect that the signals from each of the three studies would increase as the number of at bats increases.) For year-to-year comparisons, we will further require the player to be in the same league both seasons.
Correlation coefficients tell how closely related two data sets are. They range in value from 1 to – 1. A correlation coefficient near 1 indicates that when the value of a quantity from one of the sets is above its average, the corresponding value in the other set will he above its average. Similarly, when one value is below its average, the other will be below its average. Correlation coefficients do not imply cause-effect relationships. Instead, they do tell you, given the value from one data set, what kind of value you can expect in the other set. The larger the absolute value of the correlation coefficient the more likely you are to be able to predict the value from one set, given the corresponding value from the other set. For a correlation of exactly 0, the two sets are unrelated and there is no predictive value between them.
WE HAVE BROKEN the data down by league and computed the correlation coefficient for both the overall batting average and the Elias clutch rating (late-inning pressure minus overall average) for every possible pair of years, i.e., 1984-1985, 1984-1986, 1984-1987, 1985-1986, 1985-1987, and 1986-1987. Since we have six pairs of years and two leagues, we can compute twelve correlation coefficients using a cutoff of 25, 50 and 75 late-inning pressure at bats. We can then determine the degree of significance of each of these correlations. For the same correlation, the significance increases as the number of data points (players, in this case) increases. The level at which a correlation is significant tells us what chance there is that this is not a result of random chance. For example, there is a 99 percent chance that something at the 99 percent confidence level did not occur by chance, and thus we would feel pretty confident that is a real signal. For twelve correlations, we would expect one of them to be significant at the 11/12 (91.7%) confidence level just by random chance.
Table 1 summarizes the results of the correlation calculations. It gives the number of players (n) involved in each pair of data sets (i.e. for AL 1984-1985, there are 127 players who had at least 25 late-inning pressure at bats each year, and 78 who had at least 50), the correlation coefficient (r) between the two data sets (i.e. – 0.049 for the AL 1984-1985 with 25 pressure at bats), and the confidence level at which this correlation is significant (only confidence values greater than 90 percent are given).
TO PUT IT SUCCINCTLY, year to year values of the Elias “clutch” rating are uncorrelated. This is in contrast to overall batting average, which is highly correlated in all pairs of seasons. This latter conclusion is simply a reflection of the fact that people like Ty Cobb always hit for a high batting average and people like Mario Mendoza never do. In both the 25 and 75 at bat levels, there is the one correlation significant at the 91.7 percent level predicted by random chance, while at the 50 at bat level, there are only two. Of the 36 correlations for the clutch average, 16 are negative (all 36 are positive for overall average), and, in fact, the most significant correlation, between the American League in 1985 and 1986 for a minimum of 75 pressured at bats, is negative. If this were a true indicator of the situation, it would mean that rather than showing that good clutch hitters repeat their performance from year to year, good clutch hitters have a tendency to be bad clutch hitters the next year. The results of these correlation calculations imply that while an individual’s batting average is somewhat predictable from year to year, clutch hitting (by the Elias definition) is not predictable.
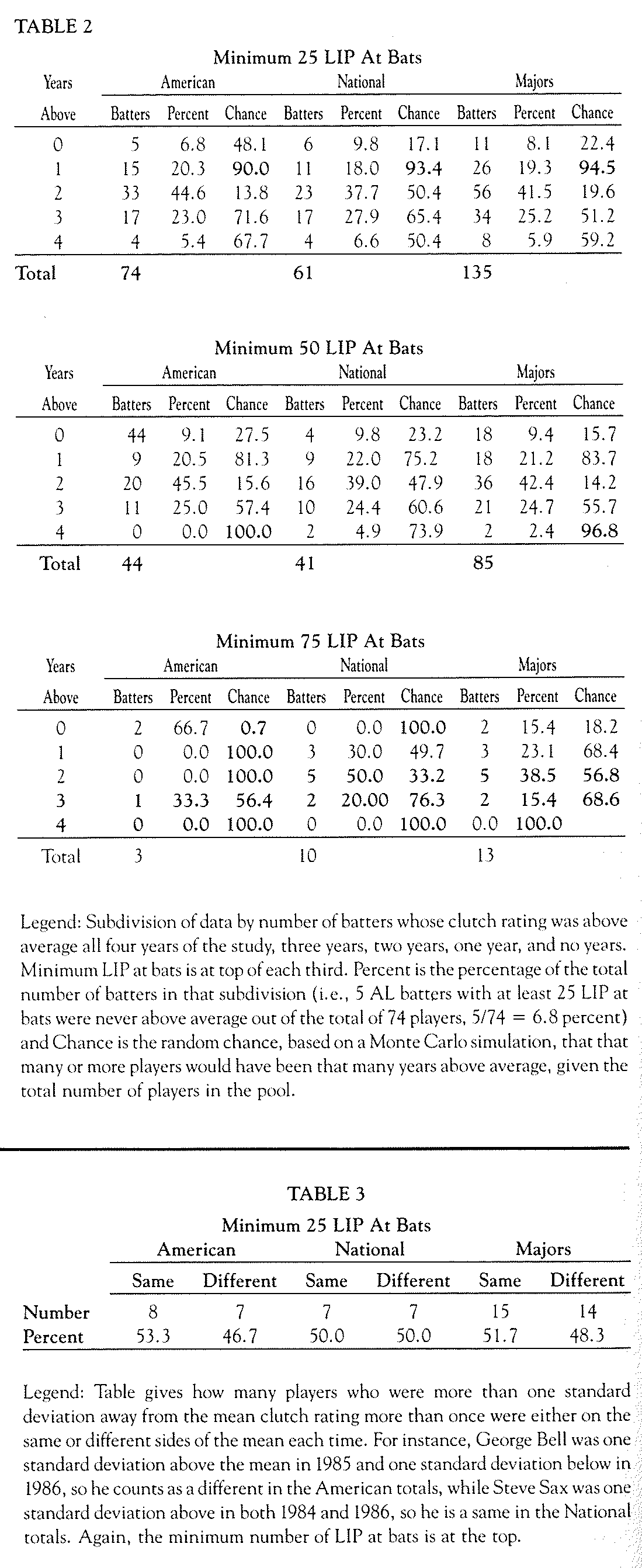
Secondly, consider the number of players who always hit better or worse than expected (according to their overall batting average) in pressure situations and compare this to the number you would get from a purely random process. Since the average player does not hit at his overall average in pressure situations, we will compare a player’s clutch rating to the average clutch rating for that year and league. If clutch hitting is random, after two years, you would expect a quarter of the players to be above average both years, a quarter below both years, and half would have one year below and one above. After three years, one-eighth of the players would be always above, three-eighths with two years above, three-eighths with one year above, and one-eighth with no years above. With the four years available for study from the “Analyst” numbers, we would expect one-sixteenth of the players at both four years and no years above, one-fourth at both three years and one year above, and three-eighths at two years above average.
Once we have counted up the number of players in each of the five categories (four years above through zero years above), we can compute the chances that any of those numbers of players would be in that category using the statistical process called a Monte Carlo simulation. Table 2 summarizes the results of these simulations. (The database is limited to players who remained in the same league for all four seasons and who had the relevant number- 25, 50 or 75- of pressured-at-bats.) The data is broken down by league and minimum pressured-at-bats. Each row of the table gives the number of players who had a certain number of years above average, the percentage of the total players that number represents and the random chance (from the Monte Carlo simulation) that you would have that many or more players in that category. (Probabilities of occurrence of at least 90 percent or at most 10 percent are in bold.)
If the Elias clutch rating is not random, you would expect to see very small probabilities of occurrence of the values at four- and zero-years-above-average- and high probabilities at two years above. Instead, what you actually see in the major league totals at both 25 and 50 at bats is that the large number of people at two years above is very unlikely. We also see that there is only a small chance that you would see only two players above their expected value for all four years at the 50 at bat level. (The sample size at the 75 at bat level is small [thirteen players] and, as a results are not particularly meaningful there, but at the lower minimum-at-bat levels, the signal is clear.) [The percentage of players in the two-year category increases from 25 to 50 at bats.] This implies that, as you increase the significance of the data, allowing players to show their “true” clutch ability, the chances of anyone being always above or always below decreases. All of these results are directly opposite to what one would expect if the Elias conclusion was correct.
Finally, we look at the issue of the players who show strong tendencies one way or the other in more than one season. First, the mean and standard deviation of clutch rating for each season and league are computed. We then consider only those players who were either above or below the mean league-clutch-rating by more than one standard deviation in two or more different seasons. In other words, we are looking at players who were among the best or worst performers more than once. One would expect, based on the Elias conclusion that a large majority of these players would be on the same side of the mean each time.
Unfortunately, that is not true. Table 3 summarizes these results, giving the number of times a player is on the same side of mean both times and the number of times he is on each side once. (There are six players —Ed Romero, Dick Schofield, Rick Dempsey, Mariano Duncan, Dave Anderson, and Jerry Mumphrey – who were more than one standard deviation away from the mean three times, using the 25 at-bat cut-off. Each pair of years was treated separately, resulting in three pairs for each player. Romero was the only one to be on the same side, above average, each of the three years. Only one player from each league made the 75 at bat cut-off. Steve Sax was above the mean both times and George Bell switched sides.)
At both the 25 and 50 at bat levels, 48 percent of the pairs have one point on each side of the mean versus 50 percent by “chance.” Once again, this is not what would be expected based on the Elias conclusion.
We have looked at the Elias definition of “clutch” hitting three different ways. In each case, the signal is clear that their definition is simply a statistical artifact with no predictive value, and that its distribution is random. We are then left with the question, “Why did Elias get the answer wrong in their 1985 article?”
It appears that having reached a conclusion before looking at the data, they did not check their data very carefully or do any real analysis of it. The data was then described in an unusual fashion to uphold their conclusion. The hints that they are wrong are there from the original article. There, they looked at the clutch ratings over ten years of ten players traditionally viewed as strong clutch hitters. One (Eddie Murray) performed 25 points better in pressure situations, one (Carlton Fisk) was 17 points worse and the other eight were no more than 11 points away from their overall average. This appears to be symptomatic of regression towards the mean, in which, as the sample size increases (number of pressure-at-bats) the deviation of the sample from its true mean decreases. (Since that time, Murray’s pressured batting average has dropped 11 points, while his overall average has dropped 2 points, and Fisk’s pressured average has dropped 5 points, with the overall average dropping 12 points. Thus, both men have decreased their deviation from the mean.)
In the Elias lists in the article of the best and worst clutch hitters of 1983 and 1984, 30 percent of the hitters change from “best to worst” in the other year. In 1988, Elias compiles lists of players who were either above or below in each of two years and then compare that to their performance in the third year, for each of four three-year periods, using a cut-off of 25 pressured at bats. Using these four trios of years, we can calculate how many players from that group were above in all three years, below in all three years, or calculate what combination of years above and years below they had. In all four cases, the number of players who were either always above average or below average was less than you would expect by random chance. (The fact that fewer than half of the “good” clutch hitters from the first two years repeated in the third year in three of the four trios was not commented upon in the article, nor was the fact that the difference in percentage above average the third year between the “good” and “bad” clutch hitters decreased in at least the 1984-1986 case when the minimum at bats were raised to 50 and changed sign when the minimum was 75, albeit with a sample of only twenty-six players.)
The evidence was there when the articles were written and the evidence has grown since the first publication. We are forced to agree almost completely with the quote from the Milwaukee comment of the 1988 “Analyst.” The only disagreement is about who is shrill and that the effort has been to prove, rather than to disprove, the existence of clutch hitting. Based upon the data published in the “Elias Baseball Analyst,” the conclusion that the Elias definition of clutch hitting is irrelevant is inescapable. Clutch hitting, as presently defined, is a mirage at best.
Harold Brooks is a Ph.D. candidate in atmospheric sciences at the University of Illinois.